What the 2025-2026 Bioinformatics Hiring Shift Means
The bioinformatics job market has undergone a structural shift that is visible in the data and felt acutely by anyone who has tried to hire or be hired in the past eighteen months. An analysis of bioinformatics and computational job postings from early 2025 found that 69 percent of available roles were for senior-level individual contributors. Entry-level positions were rare, with most junior openings being internships or temporary roles. The salary ranges for senior bioinformaticians command 130,000 to 200,000 USD at pharma and biotech companies. The roles that used to exist for a fresh master’s graduate who would run alignment pipelines and hand over count matrices have largely disappeared.
This is not a temporary tightening. It reflects a structural change in what labs and companies expect bioinformatics infrastructure to look like, and who they expect to maintain it.
There is an AI bioinformatics job paradox. Entry-level pipeline-development jobs that existed two years ago have vanished. They have been replaced by Senior Bioinformatician roles requiring four or more years of ML and AI experience. The people who used to do those pipeline jobs are being asked to compete for a completely different position.
What the Numbers Actually Show
The headline number, 69 percent of bioinformatics roles being senior-level, understates the full shift because it only reflects open positions. The more revealing signal is what is not being posted at all.
Entry-level bioinformatics roles, the ones that involved running established pipelines, maintaining alignment workflows, running DESeq2 on datasets handed down from a PI, generating count matrices and passing them upstream: these positions are declining because the work they describe is being absorbed in two directions simultaneously. Automated platforms handle an increasing fraction of the routine execution. Senior bioinformaticians who work with AI-assisted tools handle the rest.
The pharma and biotech job market in 2025 remains tight with hiring focused on specialized, mission-critical roles and a strong preference for experienced candidates. Entry-level challenges persist, with most openings requiring highly specific experience. The pattern is the same across software engineering broadly: entry-level postings in software development and data analysis have plummeted, with some data indicating a 67 percent decrease in junior tech postings since 2023, as AI tools absorb the work that used to serve as the training ground for junior professionals.
What is replacing entry-level bioinformatics is not simple automation. It is a compressed role structure where the people doing bioinformatics are expected to have both the depth of a senior analyst and the AI literacy to work with tools that have raised the minimum floor of what is considered competent practice.
What This Signals About Staffing Assumptions
The shift in hiring is not just a labor market phenomenon. It is a signal about what the industry has decided bioinformatics infrastructure should look like.
When you hire a senior bioinformatician at 160,000 USD and equip them with AI tools, you get significantly more scientific output per dollar than when you hire two junior analysts at 80,000 USD each to run pipelines. The senior analyst can evaluate results critically, design better experiments, troubleshoot failures that junior analysts would escalate, and work at the interpretation level that actually generates scientific value. The AI tools and platforms handle the mechanical execution layer.
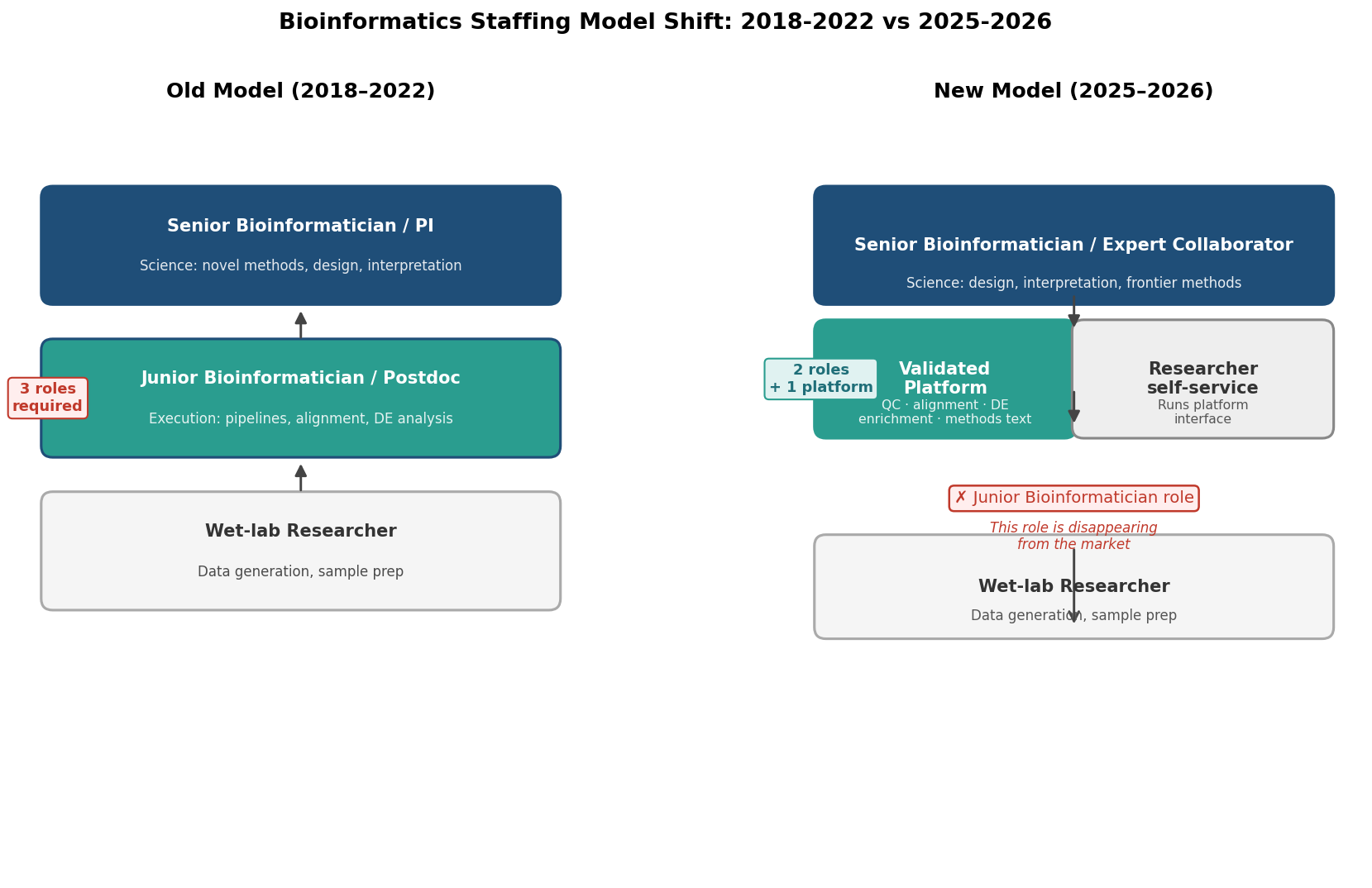
This reconfiguration has a specific implication for how RNA-seq analysis should be structured in both academic and commercial settings. The model where a junior person runs the alignment and quantification while a senior person reviews the results is being replaced by a model where platforms run the alignment and quantification and senior people review the results directly. The junior execution layer is being bypassed.
For labs that cannot afford a senior bioinformatician at all, which is most academic research groups and many small biotechs, this shift means that the self-service platform option has moved from “workaround” to “structurally appropriate response.”
The Analysis Landscape Is Bifurcating
The bioinformatics analysis landscape is splitting into two tiers that are drifting further apart.
The upper tier is what the job market now demands: people who can work at the frontier of AI-assisted genomics, who can build or evaluate novel methods, who can design multi-omic analysis strategies, and who can translate computational results into drug development or clinical decisions. These people are genuinely scarce, genuinely expensive, and genuinely necessary for the most demanding work. They are not the people who should be running routine bulk RNA-seq alignment pipelines.
The lower tier is the routine analysis that constitutes the majority of RNA-seq work: standard QC, standard alignment or pseudoalignment, standard differential expression on well-designed experiments, standard enrichment analysis. This work is well-understood, amenable to automation with validated defaults, and does not require the judgment of a 160,000 USD bioinformatician to execute correctly.
The problem is that most labs have been treating both tiers as if they require the same person. They have been hiring one bioinformatician and expecting them to run the alignment pipelines and do the frontier science simultaneously. The result is that neither gets done as well as it could.
The structural response is to separate the tiers: platforms for the execution tier, senior expertise for the scientific tier.
The platform-plus-expert-reviewer staffing pattern
The staffing model that fits the current hiring landscape is not ‘one bioinformatician who does everything.’ It is ‘a platform that handles routine execution, plus a senior analyst or collaborator who reviews results and handles the genuinely novel problems.’ This pattern is already how the best-resourced labs work implicitly. The hiring shift is making it explicit, because the junior execution role is no longer a cost-effective position to fill.
Where This Leaves the Wet-Lab Researcher
The people most affected by this shift are wet-lab researchers who need computational support but cannot compete in the senior bioinformatician hiring market.
This has always been a difficult position. The previous equilibrium, where a junior postdoc or grad student with computational interests would run analyses as a service to the lab, is deteriorating as those people leave for industry positions that have better career trajectories. The bioinformatics postdoc who used to be the computational backbone of a wet-lab group is now competing for industry roles that pay twice as much and offer better career development. Academic labs are losing these people and not replacing them with equivalents.
The structural answer for a wet-lab group in this environment is not to hire a bioinformatician who will be miserable running routine pipelines and leave within eighteen months. It is to use platforms for the routine work and reserve expert engagement for the design and interpretation stages where that expertise actually changes the scientific outcome.
This is not a diminished version of having a bioinformatician. It is a different allocation of resources to a changed landscape. A wet-lab PI who can run their own QC and differential expression through a validated platform, and who brings in expert consultation for experimental design and results interpretation, is operating more effectively in the 2025-2026 environment than one who is waiting for a junior analyst who no longer exists at the price point that fit the lab’s budget.
What This Means for How You Invest in Analysis Infrastructure
The hiring shift has a direct implication for where labs and groups should be investing their limited resources for computational analysis.
Investing in a junior bioinformatician whose primary job is routine pipeline execution is increasingly a poor use of funds. The hire is expensive relative to the value they add at the execution tier, will likely leave within two years for an industry role, and the institutional knowledge they build leaves with them.
Investing in a platform that handles routine execution automatically, combined with senior expert engagement at the stages where that expertise changes outcomes, is increasingly the cost-effective pattern. The platform does not leave. The platform does not need onboarding. The platform’s output is reproducible whether the person who set it up is still at the institution or not.
The bioinformatics career community has noticed this shift. The threads discussing the “AI bioinformatics job paradox” are not just about the job market; they are about a structural change in who is expected to do bioinformatics and with what tools. The answer that is emerging is: senior people, with platform support, working at the frontier of what those platforms cannot yet do.
For a research group evaluating where to put its next dollar of computational analysis budget, that answer suggests a platform-first approach to routine work, with expert engagement reserved for the problems that genuinely require it.
NotchBio is built for the execution tier of this bifurcated landscape. Standard bulk RNA-seq from FASTQ to enrichment analysis, validated defaults, locked reproducible runs, auto-generated methods text. It handles the work that used to justify hiring a junior analyst, without the two-year clock on when that person will leave for an industry position. The senior expert time that was previously consumed by running pipelines gets redirected to the design and interpretation stages where it has the most impact on the science.
That is not a minor efficiency gain. In the current hiring environment, it is the structural answer to a structural problem.
Related Reading
Further reading
Read another related post
Self-Service RNA-Seq For Labs Without A Bioinformatician
If your lab sequences more than it analyzes, here is what self-service RNA-seq looks like, what is safe to automate, and where you still need a human.
TutorialSTAR vs Salmon vs HISAT2: A Hands-On Benchmark
A hands-on RNA-seq aligner benchmark: working STAR, Salmon, and HISAT2 commands, real runtime and memory numbers, and how much the DEG list actually changes.
Research GuideHow To Submit RNA-Seq Results That Reviewers Cannot Reject
Reviewers reject RNA-seq papers for predictable reasons: missing FDR correction, version-less methods, inaccessible data. A checklist that prevents it.